PROJECT 01
biased language detection for Textio
Developed a new biased language detection feature for Textio’s workplace language guidance software. Constructed a phrase list with 200+ items. Built a machine learning model trained on real performance review data. The model distinguishes true from false positive instances of the feature with up to 85% accuracy. Also created a 10k+ sentence dataset by prompting ChatGPT to produce biased language during the research phase of this project.
skills: data science; NLP; machine learning; LLMs; Python
PROJECT 02
biased language labeling ontology for Textio
Developed a labeling ontology to distinguish different types of biased language. Currently writing user guidance for why and how to avoid problematic words and phrases.
skills: ontologies; sociolinguistics; qualitative research; data analysis; writing
PROJECT 03
TALK
Tools for Analyzing Linguistic Keyness or TALK is a public repository that contains a codebase for harvesting and analyzing language-based Twitter data using keyness analysis. Keyness analysis is a statistical method used to identify words that indicate what a text (e.g. a Tweet) is about. The repository also includes resources for detecting bots and creating custom stopwords lists.
skills: Python; R; Jupyter; GitHub; APIs; bot detection
PROJECT 04
keywords analysis
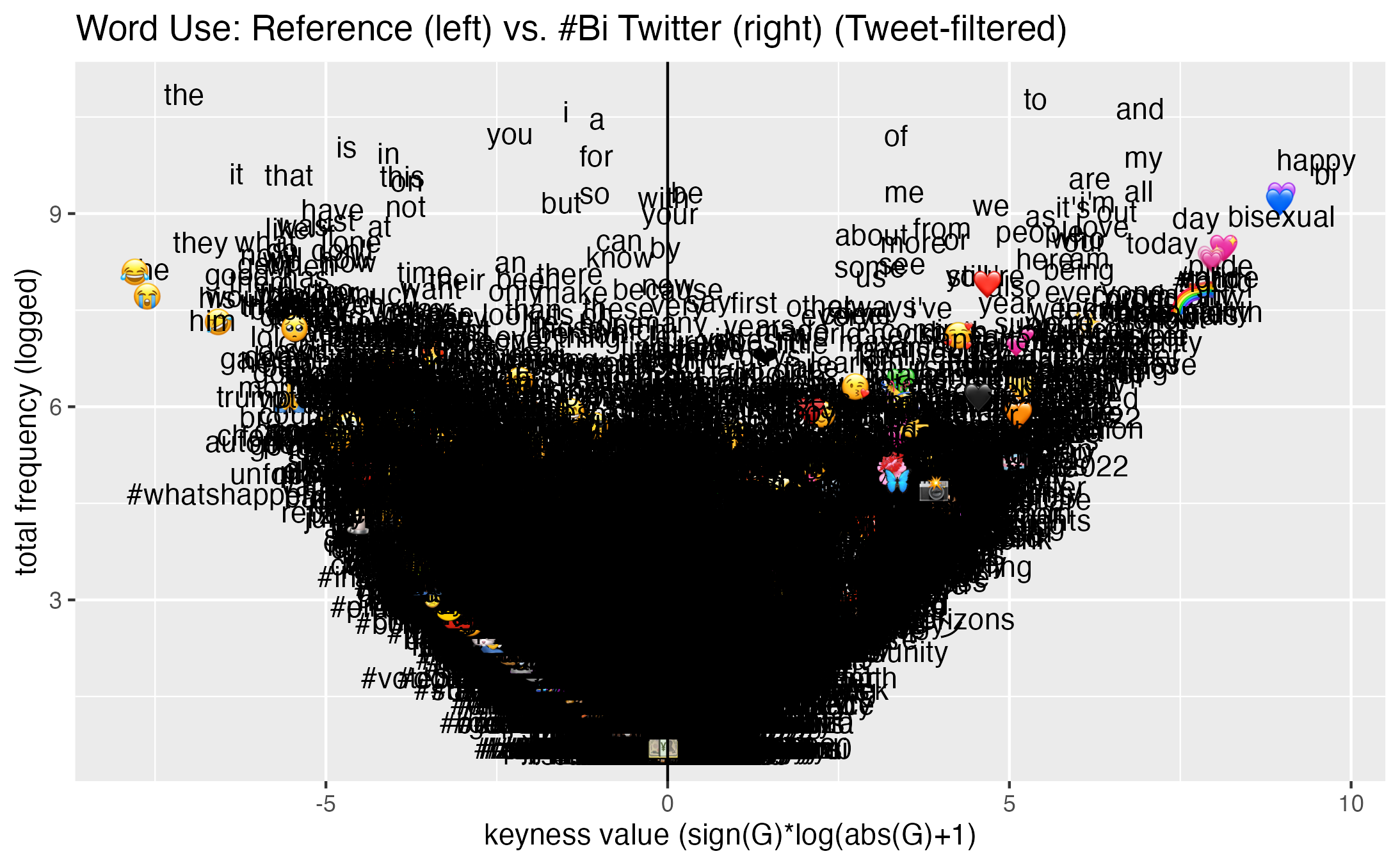
Combined quantitative and qualitative methods to examine how people talk about bisexuality on Twitter. Used the TALK codebase to harvest and clean around 700k Tweets. Analyzed the Tweets using keyness analysis (quantitative) and discourse analysis (qualitative). Details to be published in Willis & Todd (in progress).
skills: mixed-methods research; Twitter; data visualization


PROJECT 05
random forests
Analyzed /s/ data presented in Willis (2021) using random forests, a supervised machine learning algorithm. Factors included race, gender, sexuality, region, age, and more. See Willis & Ben Youssef (2023) for details.
skills: machine learning; iteration; collaboration

(Willis & Ben Youssef 2023)
PROJECT 06
discourse analysis
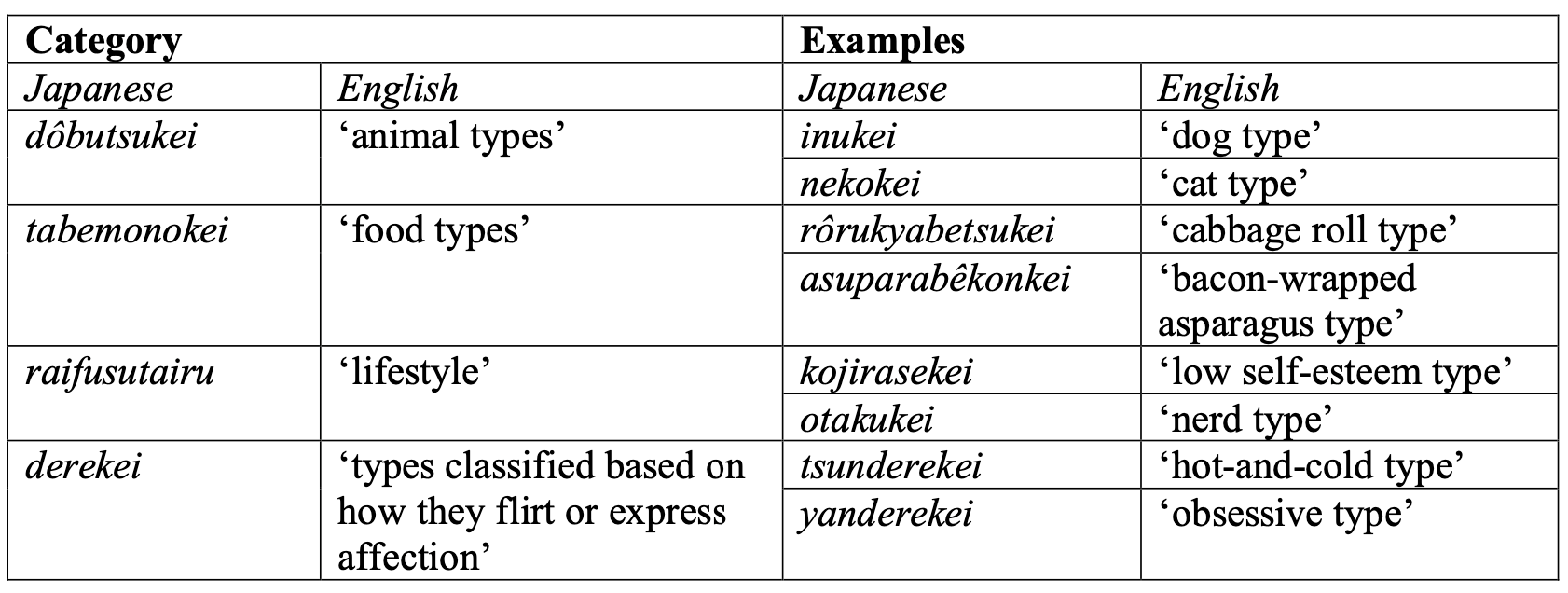
Used discourse analysis to describe, analyze, and theorize a horoscope-like taxonomy of gender identities in contemporary Japan. Analyzed digital texts, including online magazine and news articles, quizzes, YouTube videos, and Q&A posts. See the full article for more details.
skills: qualitative analysis; Japanese to English translation; writing; sociolinguistics


PROJECT 07
interviews
Conducts in-depth interviews with bisexual-identified English speakers from various backgrounds about their experiences as bisexual people. Special attention is given to how their sexuality is informed by other axes of identity, e.g. gender, trans status, and race/ethnicity. This project is ongoing, with 12 interviews so far.
skills: in-depth interviewing; analysis of human interaction
“[Bisexuality] has political ramifications and meanings for me, as well as […] teaching me about how I desire”
“[Bisexuality] means freedom and yeah it’s empowering for me to identify as bisexual”
– two participants on what bisexuality means to them
PROJECT 08
documenting under-resourced languages
My collaborators Julia Fine, Karen Tsai, and I collected 10+ hours of audiovisual data on Miyako-Ikema, an endangered Ryukyuan language. The data includes conversations, personal narratives, and tellings of folklore. I managed and mentored a team of undergraduate students to annotate this data. I also led a different team of students to translate over 4k lines of poetry from Ikema > Japanese > English at the community’s request.
skills: language documentation; community-based research; translation; project management; mentorship

PROJECT 09
music & language
Analyzed how game developers use musical and linguistic resources to balance demands for innovation and brand continuity. Used ELAN to translate and annotate video data for structural, discursive, and sociolinguistic features. Details to be published in Willis (under review) as a part of a special issue on musicolinguistics.
skills: creativity; media analysis; collaboration
PROJECT 10
acoustic analysis
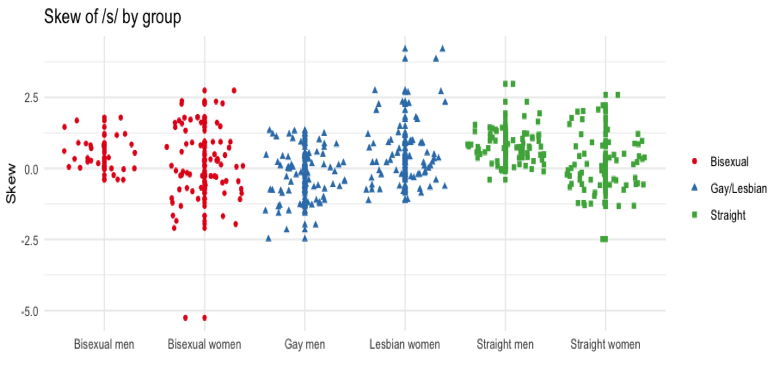
Used linear mixed-effects regression modeling to analyze how English speaking LGB and straight people produce /s/, the sound associated with the “gay lisp” stereotype. Recruited participants through local networks. Automatically extracted acoustic measurements using a Praat script. See Willis (2021) and Willis (forthcoming) for details.
skills: acoustic analysis; statistics; regression modeling; quantitative research
(Willis forthcoming)
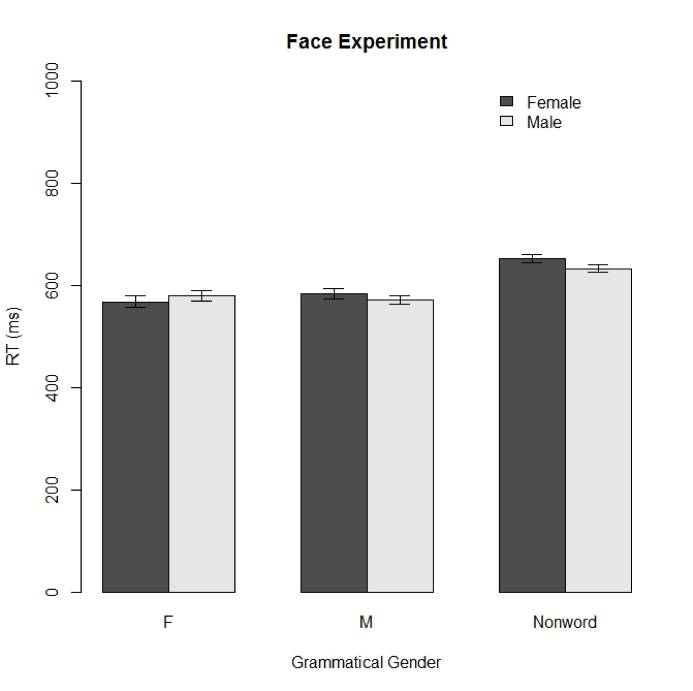
PROJECT 11
perception experiment
Explored the relationship between social information and speech perception using a Spanish lexical decision task. Found a priming effect when the gender of the speaker matched the gender of the Spanish word. Recruited speakers and participants through local networks. Recorded stimuli adapted from the Spanish Word Pool. Collected data using E-Prime.
skills: experiment design; stimuli creation